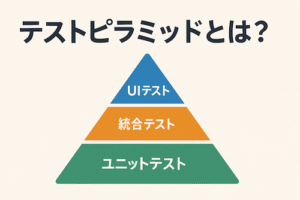
テストにお悩みの方へ
😢開発リソースが足りない...
😢リリース直前だけどテストの余裕がない
😢開発コストを抑えたい
上記のようなお悩みに対して、テスト代行サービスを運営しています。まずは無料お問い合わせください。

😢開発リソースが足りない...
😢リリース直前だけどテストの余裕がない
😢開発コストを抑えたい
上記のようなお悩みに対して、テスト代行サービスを運営しています。まずは無料お問い合わせください。
回帰影響分析を行う上で、まず重要なのはデータの収集です。特に、変更履歴データは、施策や変更がどのように結果に影響を与えたかを理解するための基盤となります。これには、ビジネスの重要な指標やパフォーマンスデータ、施策の実施日、変更の内容などが含まれます。
データ収集の方法としては、手動での記録や、各種ツールを用いた自動収集が考えられます。例えば、Google AnalyticsやCRMシステムからのデータエクスポートを活用することで、より正確かつ迅速にデータを集めることが可能です。また、データの整合性を保つために、定期的なチェックやメンテナンスも重要です。
次に、収集したデータを用いて回帰モデルを構築します。モデル学習において、特徴量は非常に重要な役割を果たします。特徴量とは、モデルが学習する際に使用する入力データのことです。例えば、施策の実施日時や、影響を受ける可能性のある外部要因(季節性や市場トレンドなど)が考えられます。
モデル学習では、適切なアルゴリズムを選択することも大切です。線形回帰やリッジ回帰、ランダムフォレストなどのアルゴリズムが一般的に使用されます。これらを用いて、どの特徴量が結果に最も影響を与えているかを分析し、モデルの精度を向上させることが目指されます。
予測精度を向上させるためには、いくつかのテクニックがあります。まず、特徴量の選択を見直すことで、モデルのパフォーマンスを改善できます。不要な特徴量を除外することで、モデルの複雑さを減らし、過学習を防ぐことが可能です。
また、ハイパーパラメータの調整も重要です。アルゴリズムにおける設定を最適化することで、モデルの性能を最大限に引き出すことができます。このプロセスは、クロスバリデーションを用いることで、より効果的に実施できます。
回帰影響分析を実施するための運用フローを構築することも重要です。このフローには、データ収集、モデル学習、予測結果の分析、施策の実施、そして結果の評価が含まれます。各ステップを明確にし、誰が何を担当するかを定義することで、プロジェクトの効率が向上します。
さらに、運用フローは継続的に見直すことが求められます。市場環境やビジネスの状況が変わる中で、フローを適応させることで、より効果的な分析が行えるようになります。定期的なレビューを通じて、フローの改善点を見つけていくことが重要です。
回帰影響分析は一度行ったら終わりではありません。継続的改善が必要です。施策の効果を定期的に評価するとともに、新たなデータを収集することで、分析の精度を継続的に高めることができます。このプロセスは、データドリブンな意思決定を促進し、ビジネス戦略の効果を最大化するために不可欠です。
また、フィードバックループを構築することで、実施した施策の結果を次の施策に活かすことができます。これにより、長期的な視点での成長を実現し、競争優位を獲得することが可能になります。
AIを活用した回帰影響分析は、データを基にした意思決定を行うための強力な手法です。適切なデータ収集とモデル学習、予測精度向上のためのテクニック、そして運用フローの構築と継続的改善が鍵となります。これらを実践することで、ビジネスの成果を最大化し、変化する市場環境に柔軟に対応できる企業を目指すことができるでしょう。
今後、AI技術の進化に伴い、より高度な分析が可能となることが期待されます。常に最新の情報をキャッチアップし、実践に活かしていく姿勢が重要です。