
はじめに
Webシステムの成長に伴い、データベースのパフォーマンス問題は避けて通れない課題となっています。特にデータ量の増加に伴い、検索のレスポンスタイムが悪化したり、バッチ処理の所要時間が増大したりする問題は、多くの現場で日々直面している課題ではないでしょうか。
MySQLにおけるパフォーマンス改善の要となるのが、インデックス設計です。適切なインデックスの設計により、クエリの実行時間を数百倍も改善できる一方で、不適切なインデックスは逆にパフォーマンスを悪化させる原因となることもあります。
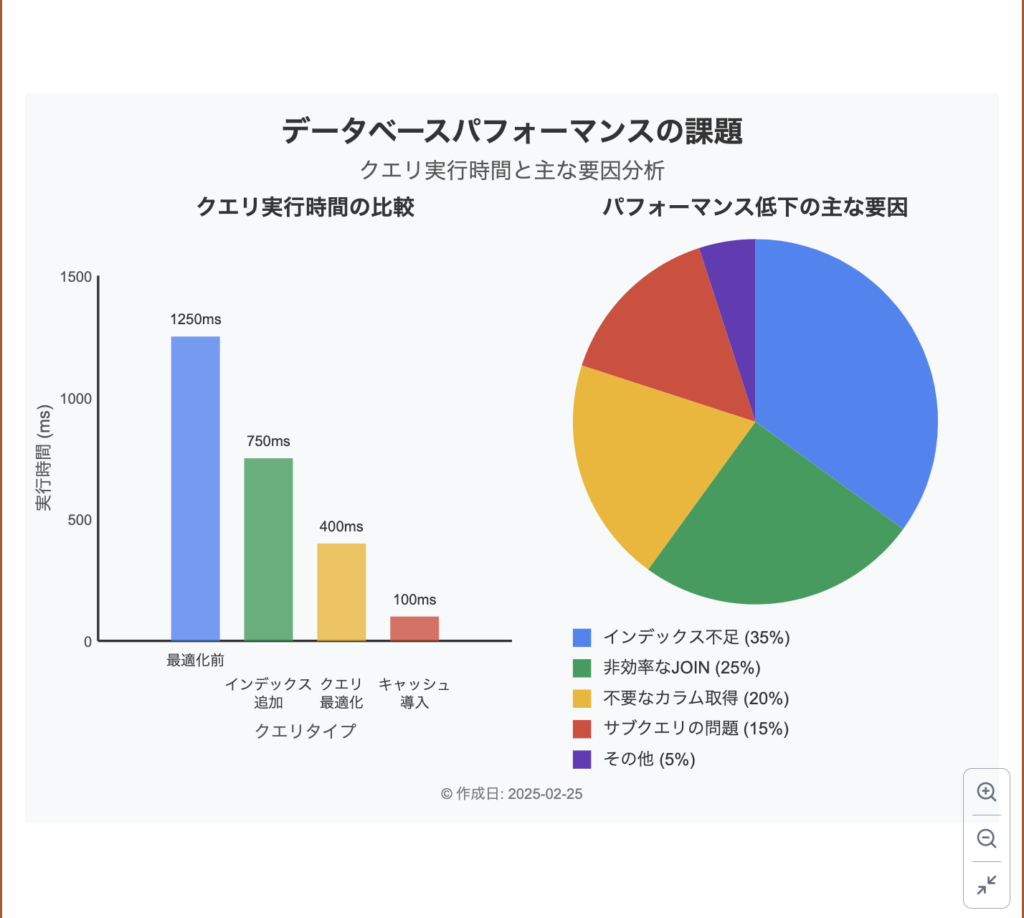
本記事では、実際の開発現場で活用できる具体的なインデックス設計のポイントと、その実践的なアプローチについて解説していきます。
1. インデックス設計の基本原則
1-1. B-treeインデックスの仕組み
MySQLの主要なストレージエンジンであるInnoDBでは、B-tree(正確にはB+tree)構造のインデックスが使用されています。この構造を理解することは、効果的なインデックス設計の第一歩となります。
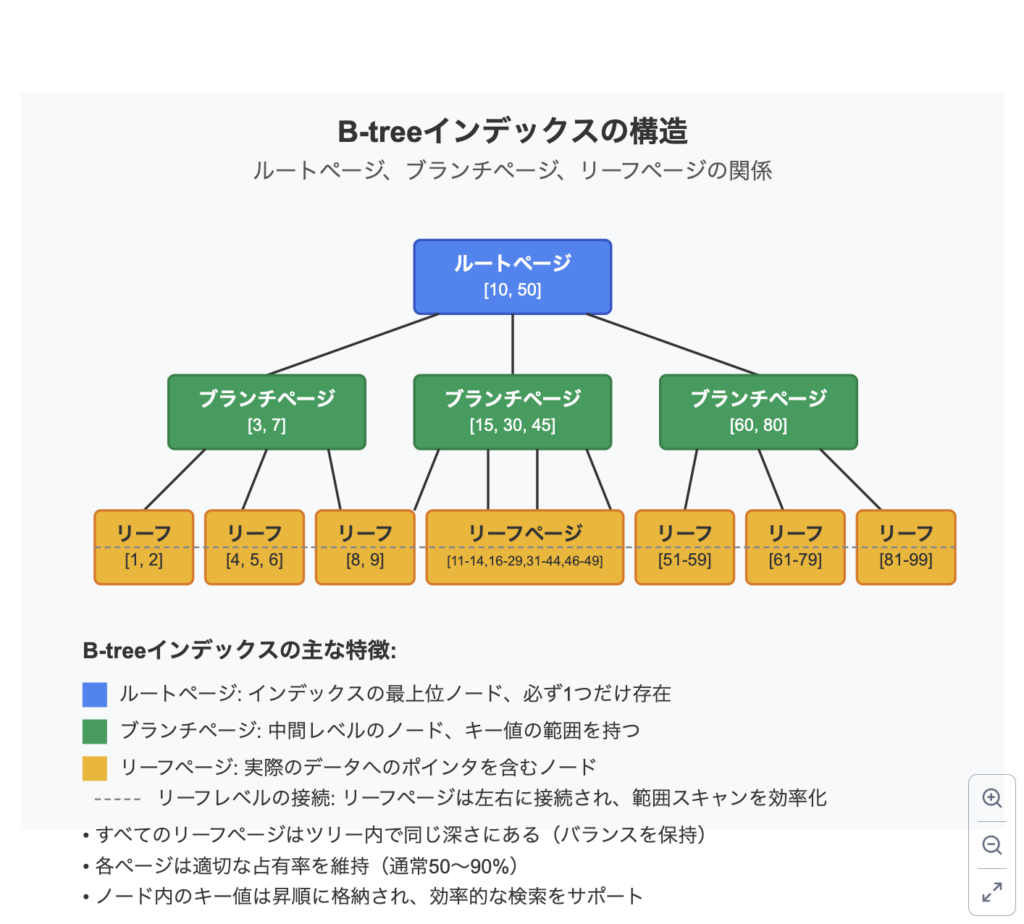
B-treeインデックスは以下のような階層構造を持っています:
- ルートページ:インデックスの最上位ノード
- ブランチページ:中間ノード群
- リーフページ:実データへのポインタを含む最下位ノード
検索時は、ルートページから順にデータを比較しながら目的のリーフページにたどり着く仕組みとなっています。
1-2. 効果的なインデックスの条件
インデックスの効果を最大限に引き出すためには、以下の3つの条件を考慮する必要があります:
- カーディナリティ(選択性)の重要性
- カーディナリティとは、カラムに含まれる値のユニークさを表す指標です
- 例:性別(低カーディナリティ)vs ユーザーID(高カーディナリティ)
- 一般的に、カーディナリティが高いカラムの方がインデックスの効果が高くなります
- 選択性の考え方
- 選択性 = ユニークな値の数 ÷ 全レコード数目安として0.1(10%)以上であれば、インデックスの効果が期待できます
- 複合インデックスの特性
- 複数のカラムを組み合わせたインデックス
- カラムの順序が重要(後述する実践ポイントで詳しく解説)
2. 失敗しない3つの実践ポイント
2-1. 実行計画を活用した設計検証
インデックスの効果を確認する最も確実な方法は、EXPLAINを使用した実行計画の確認です。
EXPLAIN SELECT *
FROM users
WHERE status = 1
AND created_at > '2024-01-01';
実行計画の重要な項目:
- type: インデックスの使用方法を示す
- const: 最も効率的
- ref: インデックスを使用した参照
- range: 範囲検索
- ALL: フルテーブルスキャン(要改善)
- key: 使用されるインデックス
- rows: 検査される行数の概算値
2-2. 複合インデックスの最適化
複合インデックスを効果的に活用するためのポイントを見ていきましょう。
-- 改善前:非効率なインデックス構成
CREATE INDEX idx_status_created ON users (status, created_at);
-- 改善後:検索条件を考慮したインデックス
CREATE INDEX idx_created_status ON users (created_at, status);
カラム順序の決定基準:
- 等価条件(=)で使用されるカラムを先頭に
- 範囲条件(>, <)で使用されるカラムは後方に
- ORDER BYで使用されるカラムの順序も考慮
2-3. 運用フェーズでのモニタリングと改善
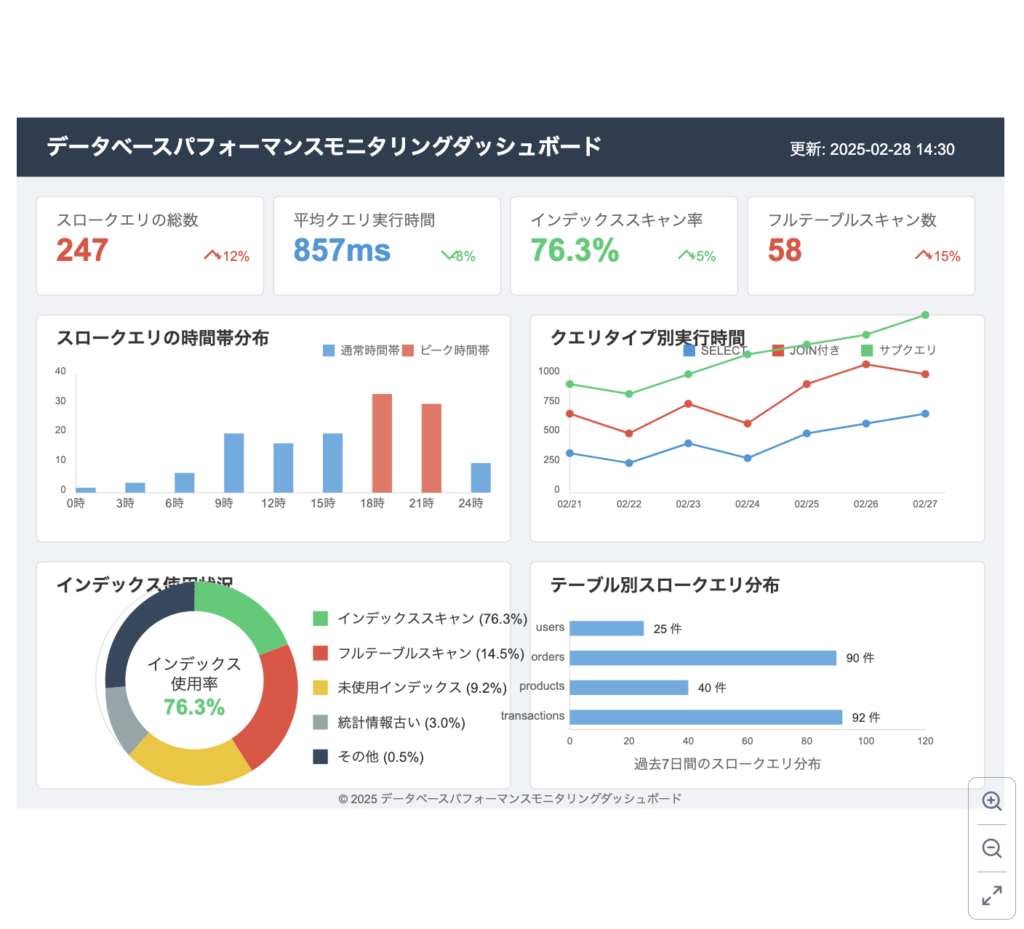
効果的なモニタリングのポイント:
- スロークエリログの設定
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1; -- 1秒以上のクエリをログ
- インデックス使用状況の確認
SELECT * FROM performance_schema.table_io_waits_summary_by_index_usage
WHERE object_schema = 'your_database_name'
ORDER BY count_star DESC;
- 定期的なメンテナンス
- ANALYZE TABLE: インデックス統計情報の更新
- OPTIMIZE TABLE: テーブルの最適化
3. 実装例と具体的な改善事例
3-1. Eコマースサイトでの改善事例
ある大手Eコマースサイトでの受注検索機能の改善事例をご紹介します。
課題:
- 注文履歴検索のレスポンスが遅い(平均3秒)
- 特に日付範囲検索で顕著な遅延
解決アプローチ:
-- 改善前の状態
CREATE INDEX idx_order_date ON orders (order_date);
CREATE INDEX idx_customer_id ON orders (customer_id);
-- 改善後:複合インデックスの作成
CREATE INDEX idx_customer_order_status ON orders
(customer_id, order_date, status);
改善結果:
- 検索レスポンス:3秒→0.1秒
- データベース負荷:CPU使用率30%減少
3-2. バッチ処理の最適化事例
大規模データの集計バッチ処理における改善事例です。
実装のポイント:
-- パーティション範囲を考慮したインデックス
CREATE INDEX idx_batch_process ON large_table
(process_date, status, id)
PARTITION BY RANGE (TO_DAYS(process_date)) (
PARTITION p_2023 VALUES LESS THAN (TO_DAYS('2024-01-01')),
PARTITION p_2024 VALUES LESS THAN (TO_DAYS('2025-01-01'))
);
改善効果:
- 処理時間:4時間→40分
- ディスクI/O:60%削減
4. よくある失敗パターンと対策
- インデックスの過剰作成
- 問題点:更新処理の遅延、ディスク使用量の増加
- 対策:定期的なインデックス使用状況の分析と整理
- 不適切なカラム順序
- 問題点:インデックスが有効に機能しない
- 対策:WHERE句の条件とORDER BY句を考慮したカラム順序の設計
- 更新処理への影響考慮漏れ
- 問題点:INSERT/UPDATE性能の低下
- 対策:更新頻度とクエリ実行頻度のバランス考慮
- 運用面での注意点
- インデックス再構築のタイミング
- 統計情報の更新頻度
- ディスク容量の監視
まとめ
本記事で解説した3つの実践ポイントを再確認しましょう:
- 実行計画を活用した設計検証
- 複合インデックスの最適化
- 継続的なモニタリングと改善
これらのポイントを意識しながら、実際のシステムに適用していくことで、パフォーマンスの改善と安定した運用を実現できます。まずは以下のステップから始めることをお勧めします。
- 現在のクエリパフォーマンスを計測
- スロークエリログの有効化と分析
- 重要なクエリから順次インデックスの見直し
参考資料・ツール
- MySQL 8.0 リファレンスマニュアル
- MySQL Workbench – インデックス設計・分析ツール
- pt-query-digest – クエリ分析ツール
システムの規模や要件に応じて、適切なアプローチを選択していくことが重要です。まずは小規模な改善から始めて、段階的にパフォーマンスを向上させていくことをお勧めします。


